I’ve been using LastPass as a password manager since 2012 and even paid for the Premium subscription, so I could access it from my phone. That specific feature later turned free, and has recently turned paid again. It’s not that I’m unhappy with LastPass per se, or that I wouldn’t want to pay for the service again. I’ve just had my eye on an alternative with a bit more control in the past, e.g. self-hosted Bitwarden. I never did get around to doing it however. It just seemed like a little too much effort for little gain.
That being said, ever since a colleague introduced me to The standard unix password manager, pass, I’ve started to use it alongside LastPass and think it’s a brilliant tool. For that reason, I’ve been wanting to do a setup based on it, to replace LastPass entirely.
Overall pass mostly offers the same core feature as LastPass, in the sense that it provides a means to store a collection passwords or notes in an encrypted manner. LastPass has a few more bells and whistles though. To name a few I’ve found useful:
- Automatic synchronisation between devices.
- Access from mobile.
- Autofill in the browser.
Export / Import
Luckily getting passwords out of LastPass is very easy. The extension provides a direct file download from Account Options > Advanced > Export > LastPass CSV File.
The question is then, how to move the content of this file into pass‘ ~/.password-store.
There’s no support for importing random CSV files in pass itself, so my first thought was to write a small script, that would go through the file line by line and issue the corresponding pass insert commands for each entry.
Before doing that, luckily I came to my senses and looked for existing solutions first.
On the homepage of pass there’s a link to an extension for this very problem; pass-import and it supports importing from a LastPass vault. It’s not written by the author of pass though, so the question is whether it can be trusted?
Deciding to feed the entirety of your passwords portfolio to some tool you’ve found online shouldn’t be done lightly, but given the fact that it is linked from the official homepage and appears to have some activity and approval on GitHub, does make it seem trustworthy.
I did look a bit through its source as it appears on GitHub, but didn’t really know what specifically to look for. Also I didn’t find anything that smelled outright like, “send this file over the internet”. For that reason, and the above, I decided to throw caution to the wind and give it a go.
Installing the extension
My install of pass comes from Homebrew, but unfortunately only the pass-otp and pass-git-helper extensions seems to be available as formulae:
$ brew search pass
==> Formulae
gopass lastpass-cli pass-otp ✔ passwdqc
gopass-jsonapi pass ✔ passenger wifi-password
keepassc pass-git-helper passpieBummer… It is available from pip though:
pip3 install pass-importThis way of installing it doesn’t integrate with pass in the normal way however:
$ pass import
Error: import is not in the password store.Not to worry, it is possible to invoke the extension directly instead:
$ pimport pass lastpass_export.csv --out ~/.password-store
(*) Importing passwords from lastpass to pass
. Passwords imported from: /Users/rene/lastpass_export.csv
. Passwords exported to: /Users/rene/.password-store
. Number of password imported: 392Marvellous! All of my LastPass vault is now in the pass store.
Missing features
Most important of all is probably synchronising the store between different machines, so let’s take a look at that first.
LastPass synchronises its vault via its own servers. With pass you could achieve something similar, by putting your store on Dropbox or Google drive for instance, but there’s another alternative I think is even better. There’s an option in pass to manage your store as a Git repository and as such, it would allow pushing and pulling from a central Git server.
Now the point of this whole exercise, is to have a solution that provides a lot more control and even though everything in the pass store is encrypted, pushing everything to e.g. GitHub, defeats the purpose somewhat.
Gitea
I’ve opted to self-host an instance of Gitea and use it to host the Git repository for my pass store. UI wise It’s a lightweight clone of GitHub, so it appears very familiar. I won’t get into the specifics of how to set it up here, but the official docs are quite good on that front anyway; Installation with Docker.
The man page for pass, has a very good example of migrating the store to use git in the “EXTENDED GIT EXAMPLE” section.
Whether you choose to self host or use another service for Git, after you’ve initialised the repository through pass and done an initial push, everything should show up in your remote. Encrypted of course.
Cloning the repository on a new machine and copying over your GPG key is basically all that is really needed. Here’s an example moving a GPG key from one machine to another:
hostA $ gpg --list-keys # Find the key-id you need
hostA $ gpg --export-secret-keys key-id > secret.gpg
# Copy secret.gpg to hostB
hostB $ gpg --import secret.gpgYou might need to trust the key on the new machine, but now synchronising additions and removals from the store, is just a git push/pull away.
What about mobile?
I’m an Android user, so for me it turns out this is an easy addition. You only need two apps:
Password Store handles the git interactions and browsing of the password store, whilst OpenKeychain allows you to import your GPG key to your phone.
That part was definitely easier than expected, but obviously this is assuming your phone can reach your git server. I put my Gitea installation on a publicly resolvable hostname, so this was not a problem in my case. Using a VPN client on the phone might also be an option, if you don’t want anything public facing.
The Password Store app doesn’t seem to do autofill, but to be honest, the way overlays work in Android is kind of annoying anyway. I don’t suspect I’ll miss it. A bit of copy pasting is fine by me.
Edit 21/03/21: The Password Store app does support autofill! I just didn’t see it in the input field drop-downs alongside LastPass when I did my initial testing as it is not enabled by default. My apologies for the misinformation.
There’s a radio toggle in Settings > Enable Autofill and enabling it will add Password Store as a system wide Auto-fill service:
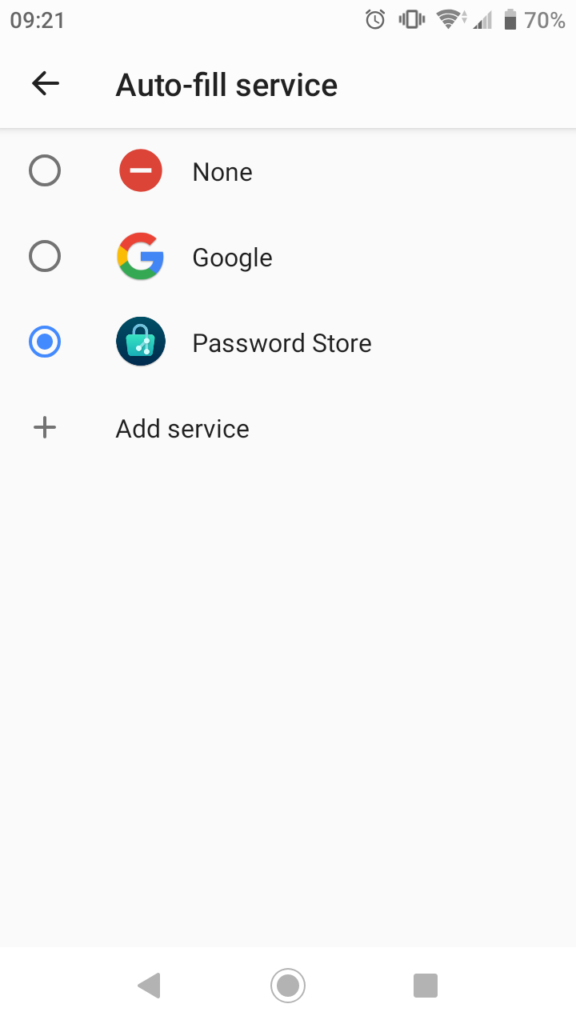
It works similarly to the way LastPass worked, where you can invoke it from an empty input or password field in other apps.
Wrap up
As of today LastPass is gone from my phone, but I’ll keep the browser extension on the desktop around for a little while. Just as a backup.
On the subject of browser extension, there is the browserpass-extension. It requires a background service to interface with pass, which is to be expected, but also a little messy, so for now I’ll see if I can get by without it.
Links
- LastPass
https://www.lastpass.com - pass – the standard unix password manager
https://www.passwordstore.org - pass import
A pass extension for importing data from most of the existing password manager.
https://github.com/roddhjav/pass-import - Gitea – Git with a cup of tea
https://gitea.io/en-us/ - Password Store
https://github.com/android-password-store/Android-Password-Store - OpenKeychain
https://www.openkeychain.org